


Introduction
In this blog, we are going to delve into the topic of context switching in operating systems. We will explore the basics, seeking answers to the questions 'What?' 'Why?' and 'How?' to understand how things work. By breaking down this complex topic into more manageable subtopics, we aim to enhance our understanding of the fundamentals.
What is Context Switch?
Context Switching is the technique using which the operating system can switch the processes.
When the context switch happens it stores the state of the current process inside the process control block (PCB).
I know this could be confusing. So, let's break it down and delve into what happens internally. We'll also familiarize ourselves with some key terminology such as 'process' and 'process control block'.
What is a process?
A process is a program under execution.
Let's say you write a C++ code, pass it to the compiler and the compiler provides us with an executable file, for the CPU to run that executable file, it will create a process. So our C++ program is under execution inside the CPU.
Now, let's dissect what constitutes a process. To understand the meaning and implications of starting a process, we must first understand its composition.
The architecture of the process?

Text Section (Code Segment)
This area stores the actual binary code of the program. It includes the compiled program code, processed by a compiler.
For instance, when you compile your C++ program, it results in an executable file in binary format. This is the file that we are referring to here, denoted as
(.exe), not the source code file, which is denoted as(.cpp).
Data Section (Global Segment)
This area contains static or global variables that have been initialized by the programmer. They retain their value throughout the lifetime of the program.
For example, in a C++ program, we often define global variables like the value of
PIor a specific constant that remains unaltered or maintains a single instance throughout the program's execution.#include <iostream> using namespace std; // Global variable declaration: const double PI = 3.141592653589793; int main() { // PI can be used anywhere in the program from here onwards. cout << "The value of PI is: " << PI << endl; return 0; }
BSS (Block Started by Symbol) Segment
This segment contains the global and static variables that are uninitialized. They are automatically initialized to zero. Let's understand this with an example
#include <iostream> using namespace std; // Uninitialized global variable int globalVar; int main() { // Uninitialized local static variable static int staticVar; cout << "The value of uninitialized global variable is: " << globalVar << endl; cout << "The value of uninitialized static variable is: " << staticVar << endl; return 0; }
Heap Section
This is the section of memory that is dynamically allocated. When your program runs and you use
new(in C++) ormalloc(in C) or similar constructs in other languages, the memory is allocated from the heap.It is used for dynamic memory allocation. This becomes essential when there is a need to allocate additional memory space during runtime. That's where the heap comes in, facilitating dynamic memory allocation in real time.
However, it's important to remember to deallocate this memory once the need for it has been satisfied, otherwise, you could run into memory-related issues.
#include <iostream> using namespace std; int main() { int* p = new int(29); // Dynamically allocate memory and initialize to 29 cout << "Value of p: " << *p << endl; delete p; // Deallocate memory when done return 0; }
Stack Section
This contains data that helps keep track of function calls, parameters, local variables, and return addresses.
The stack is used in a last-in-first-out (LIFO) manner, where items are pushed (added) and popped (removed) from the top of the stack. Each thread gets its stack. For instance In this code, when
function(x)is called inmain, a new stack frame is created for thefunction. This frame contains the parameterx, the local variabley, and the return address (the point in themainto return to afterfunctionfinishes). Oncefunctioncompletes its execution, its stack frame is removed, and execution continues inmainat the point right after the call to function#include <iostream> using namespace std; void function(int x) { int y = x + 5; // local variable cout << "The value of y is: " << y << endl; } int main() { int x = 10; // local variable function(x); // function call return 0; }
What is a PCB?
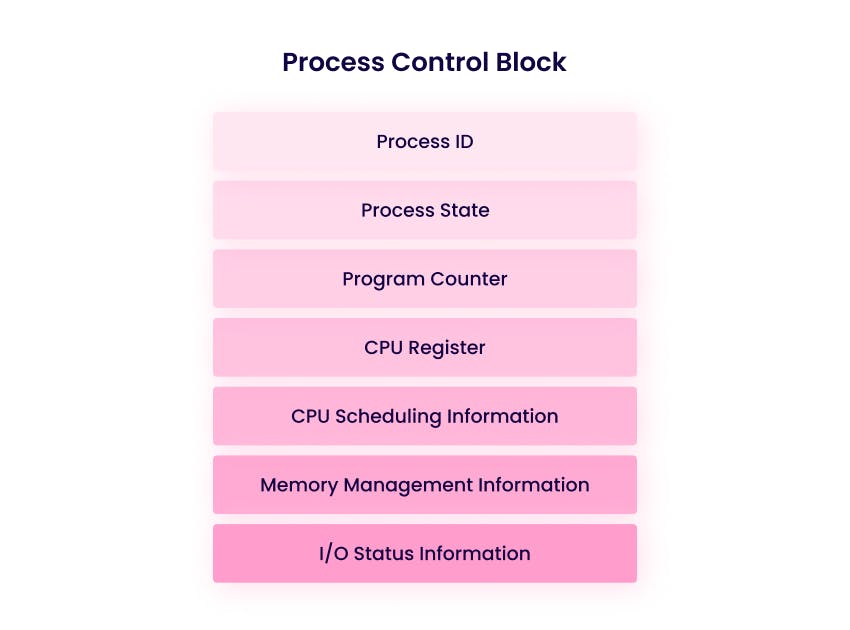
A Process Control Block (PCB), is a data structure maintained by the operating system for every process in the system. In a nutshell, the PCB stores everything the operating system needs to know to manage a process.
So now let's understand what this data structure stores about the process and how it helps the operating system.
Process ID (PID)
A unique identifier that distinguishes one process from another, facilitating process tracking and management.
To check the processes running on Windows computer you can use the below command.
tasklist
Process State

The current status of the process.
The OS uses this data to decide what actions should be taken for the associated process let's understand what each state means.
New: The process is being created.
Ready: The process is waiting to be assigned to a processor.
Running: Instructions are being executed.
Waiting: The process is waiting for some event to occur (such as an I/O operation).
Terminated: The process has finished execution.
Program Counter
The address of the next instruction in the process that needs to be executed.
When a process is running, the CPU fetches the instruction at the address stored in the Program Counter, executes it, and then updates the Program Counter to point to the next instruction.
For instance, we have 3 instructions inside a program
Instruction A,Instruction B, andInstruction C. When the program starts running, the Program Counter, points toInstruction A. AfterInstruction Ais executed, and the Program Counter is updated to point toInstruction B, and so on. In context to C++, this instruction could be initializing a variable, calling a function or controlling flow statements.
CPU Registers
The data in all the processor registers are saved at the time of the last context switch. These are saved to allow the process to be continued later from the same point.
For instance, we have a process running that will perform the addition of two numbers the number to be added might be stored in
2 data registers(small storage area inside the CPU that holds the data that is being processed),Register AandRegister B. Furthermore, we have a 3rd registerRegister Cwhich stores the result of the addition.Now suppose an interrupt occurs (like a timer interrupt), triggering a context switch. The operating system decides to pause the current process and switch to another process. Before the switch, the operating system saves the current state of all registers for the current process in its Process Control Block (PCB). This includes the values in
Register AandRegister B(the numbers to be added) and any existing value inRegister C.The OS then loads the state of the registers for the new process (which were saved in its PCB during its last context switch).
CPU Scheduling Information
Includes priorities, scheduling queue pointers, and other scheduling parameters. This helps us in determining how the CPU's time should be allocated to different processes.
For instance, we have 2 Processes
Process AandProcess B,Process Ahas a priority of 5 andProcess Bhas a priority of 10. The operating system using a priority-based scheduling algorithm will choose to runProcess Bfirst thenProcess AasProcess Bhas a higher priority.Without this information, the operating system would lack a systematic way to allocate CPU time, which could result in inefficient CPU utilization and poor performance.
Memory Management Information
Memory allocation details, such as page tables and memory limits, play a pivotal role in process management.
They ensure each process can access its memory without interference, ensuring accurate data access. For example, without proper memory management, a memory-intensive game like
PUBGcould potentially overwrite memory allocated to lighter applications likeDiscord, or monopolize system memory, leading to crashes in other applications.Therefore, memory management information in the process control block is crucial for system stability and balanced resource utilization.
I/O Status Information:
Includes the list of I/O devices allocated to the process, a list of open files, etc.
It's necessary to manage input/output operations for a process and keep track of the devices and files associated with it.
Reasons for Context Switching
Multitasking

Multitasking allows multiple processes or threads to share CPU time.
For example, while studying, you might use Microsoft Word
(Process 1)for writing and simultaneously listening to music on Spotify(Process 2). The operating system switches between these processes, allowing each to execute their instructions.
Higher Priority Task
Preemption occurs when a higher-priority task becomes ready.
For instance, when you are listening to
musicon your smartphone and receive aphone call, the operating system switches the context to prioritize thephone call. The music playback is paused, and the focus shifts to the call.
Interrupts and system calls

Interrupts and system calls require context switches to handle events and services.
When a
digital camerais connected to a computer via USB, it generates an interrupt signal, prompting the operating system to execute aninterrupt handler routine.This routine initializes the necessary drivers and services to establish a connection between the camera and the computer.
Resource wait
Resource wait occurs when a process requests a resource that is not immediately available.
For instance, while downloading a file in a browser, if you receive a call, the context switches to focus on the call, and the download pauses due to the lack of available resources. Once the call ends, the context switches back to resume the download.
Time Quantum

In preemptive scheduling algorithms, each process is allocated a fixed amount of CPU time called a
quantum.When a process's quantum expires, a context switch may occur to allow another process to run. This prevents a single heavy process from monopolizing the CPU and ensures fair execution for all processes.
The Context Switching phases?
The process of context switching involves a series of steps managed by the operating system's scheduler. Here is a simplified step-by-step breakdown of what typically happens during a context switch:
System Request
A context switch begins when the running process is preempted (usually because its time slice has expired or a higher priority process has become ready to run), or when the running process makes a system call or is interrupted.
Store Current Process State
The operating system's scheduler stores the state of the currently running process in its Process Control Block (PCB).
This includes data such as the process's priority, its state (e.g., running, waiting), and its CPU registers (e.g., the program counter, stack pointer, and other registers).
Select New Process
The scheduler determines which process should run next.
This decision is based on factors such as process priority and scheduling algorithm (e.g., round-robin, priority scheduling, etc.).
Load New Process State
The state of the new process, which has been stored in its PCB, is loaded into the CPU's registers.
This prepares the new process to start executing where it last left off.
Execute New Process
The new process begins to execute.
Conclusion
In summary, context switching plays a crucial role in the management of processes and threads within an operating system. It allows a single CPU to handle multiple tasks almost simultaneously, achieving what we perceive as multi-tasking in computer systems.